McEval is the first massively multilingual code evaluation benchmark (from human handwriting) covering 40 languages (16K samples in 44 total), encompassing multilingual code generation, multilingual code explanation, and multilingual code completion tasks.
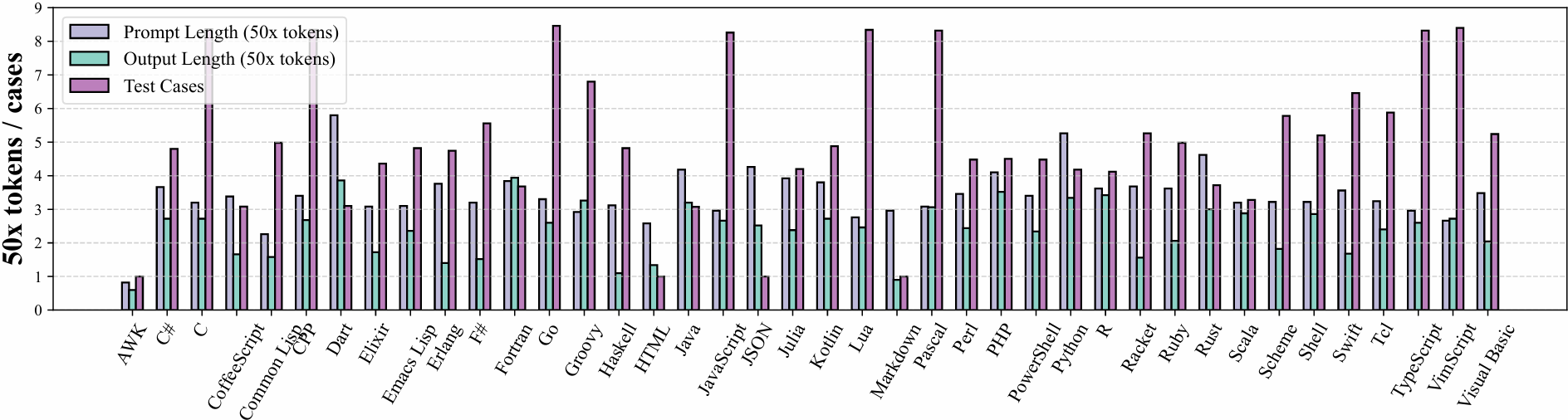
We plot the length of input length, the length of output, and the number of test cases of each programming language. The multilingual code generation and explanation tasks separately contain 2K samples, where each language has nearly 50 samples. The code completion task can be decomposed into multi-line completion (3K samples), single-line completion (3K samples), span completion (4K samples), and span completion (light) (2K samples).
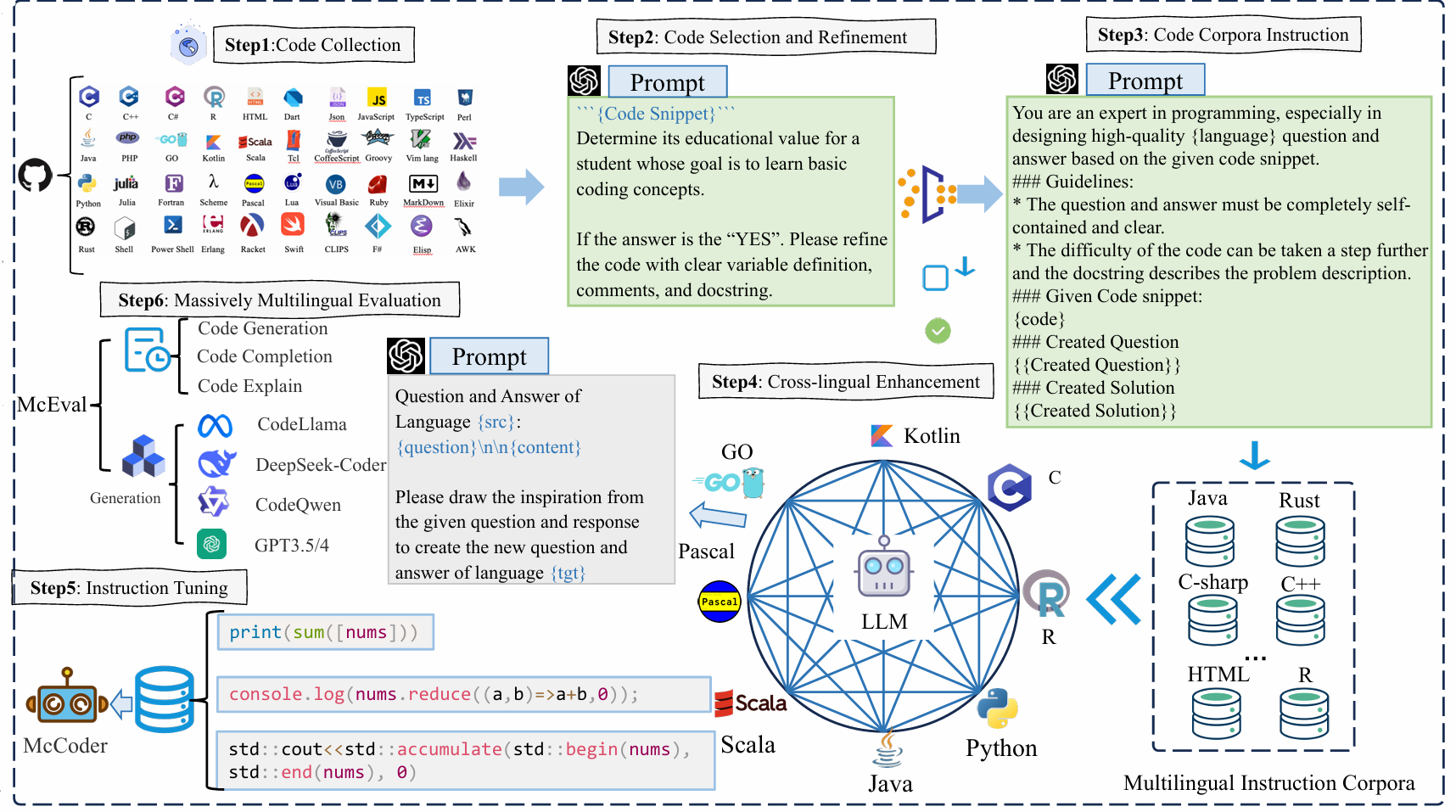
To create the massively multilingual code evaluation benchmark McEval, the annotation of multilingual code samples is conducted utilizing a comprehensive and systematic human annotation procedure, underpinned by rigorously defined guidelines to ensure accuracy and consistency. Following a detailed training session on the annotation protocol, which emphasizes the importance of context, syntactical correctness, and semantic fidelity across languages, annotators are tasked with creating problem definitions and the corresponding solution.
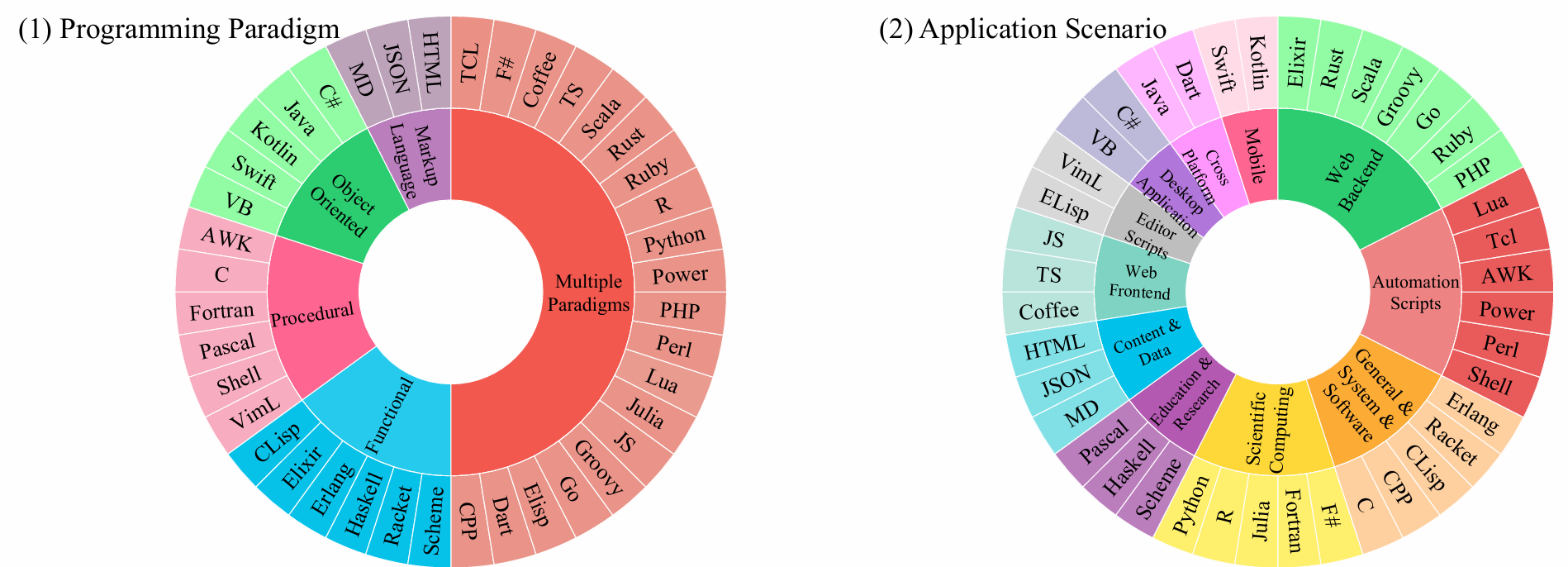
We categorize the programming languages of McEval into 5 programming paradigms and 11 application scenarios and summarize the performance of code LLMs on the code generation task.
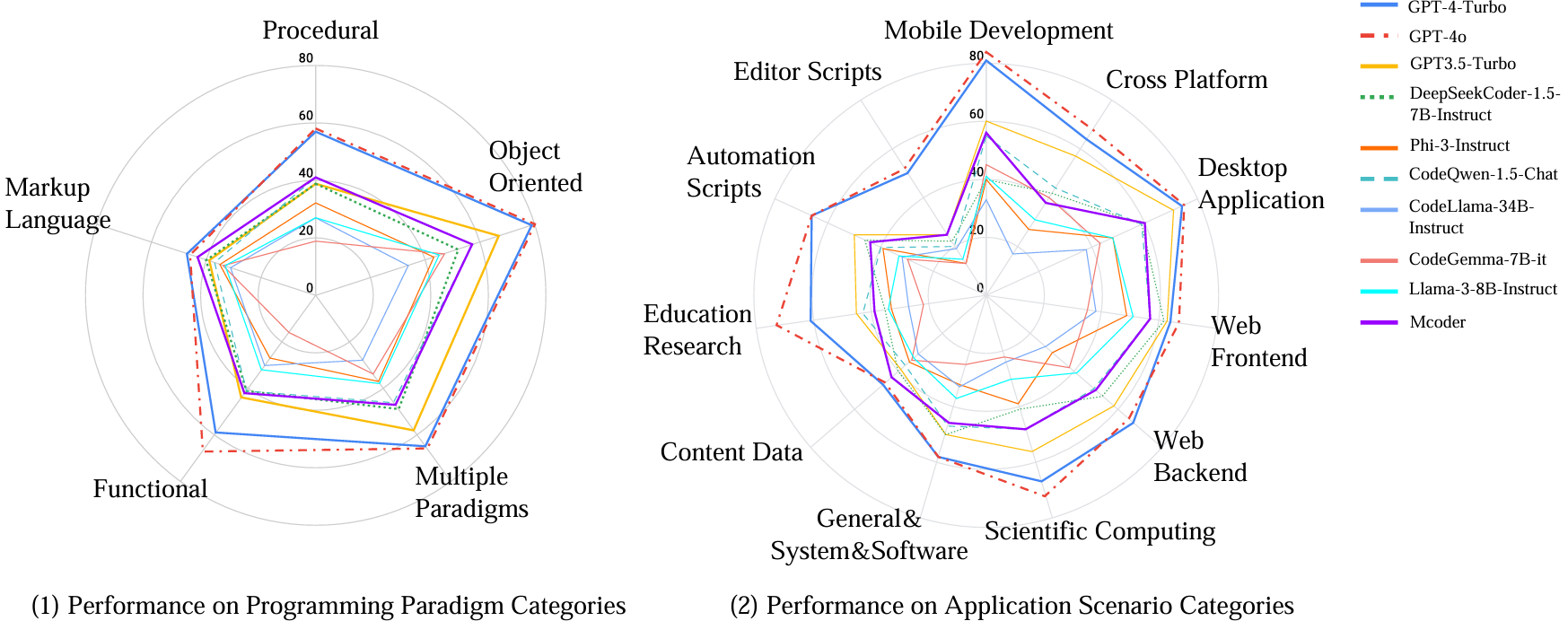
It can be observed that code LLMs generally perform better in object-oriented and multi-paradigm programming languages (high-resource languages), while perform worse in functional and procedural programming languages (low-resource languages). In areas like web development and scientific computing, the gap between open-source and closed-source models is narrowing. However, for application scenarios, there is still a substantial gap between open-source models and the closed-source GPT-4 series in low-resource languages related to scripting, mobile development, and educational research. mCoder performs superior over multiple same-size models and even some larger open-source models.
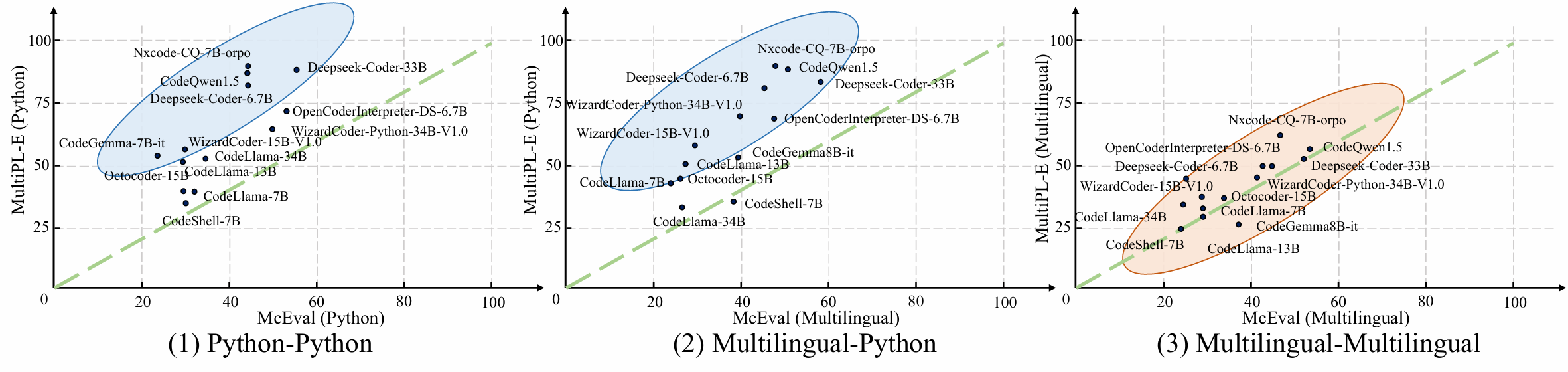
We compare the results of several open-source models on the Multipl-E multilingual benchmark with corresponding languages on McEval. We obtained scores for 11 programming languages (including Python, Java, JavaScript, C++, PHP, Rust, Swift, R, Lua, Racket, and Julia) from the BigCode leaderboard. As shown in Figure (1), due to the simplicity of Python language tasks in this dataset, many models exhibit significant score discrepancies between the two benchmarks. By examining Figure (2) and (3), it becomes evident that all models demonstrate consistent multilingual capabilities between Multipl-E and McEval. However, Figure (2) highlights a majority of models within the blue circle, indicating that the current state-of-the-art performance of most models primarily lies in high-resource languages like Python, while their proficiency in low-resource languages awaits further exploration and enhancement.
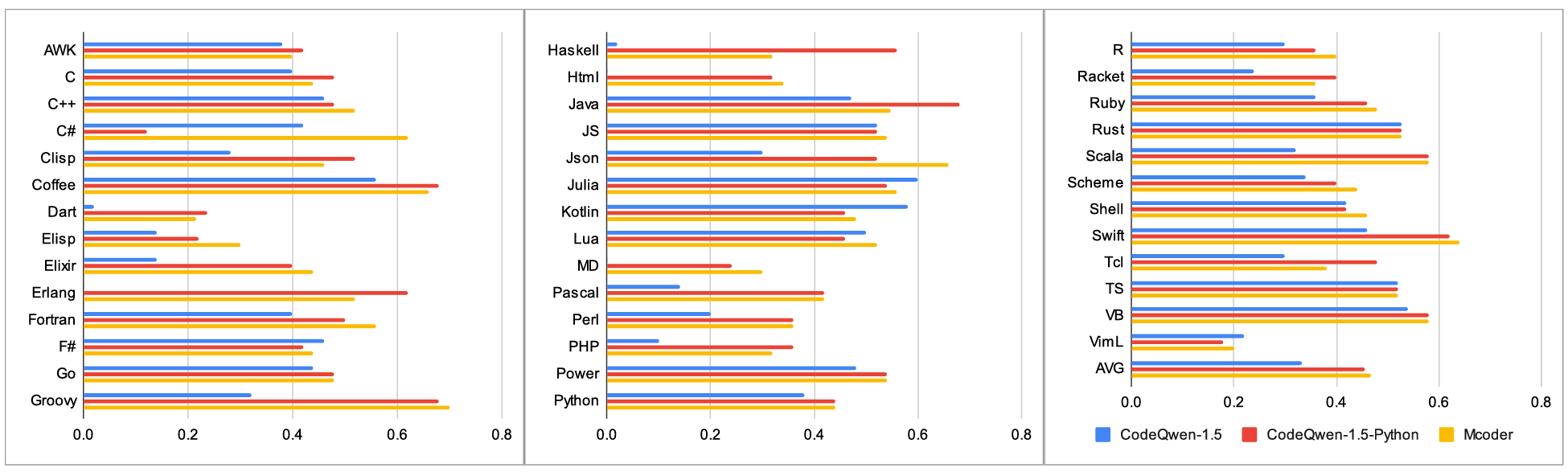
We fine-tune the CodeQwen-1.5 model using Python-only data in McEval-Instruct and compare it with mCoder. CodeQwen-1.5 performs well in most high-resource languages, but CodeQwen without alignment exhibits unsatisfactory results in some low-resource languages due to the inability to follow instructions. As such, with fine-tuning using only Python data, CodeQwen-1.5-Python improves significantly across most languages. It shows that the CodeQwen foundation model already possesses strong coding capabilities but lacks adequate instruction-following skills. Therefore, fine-tuning with Python-only data can still effectively transfer instruction-following abilities to other languages, resulting in superior multilingual performance.

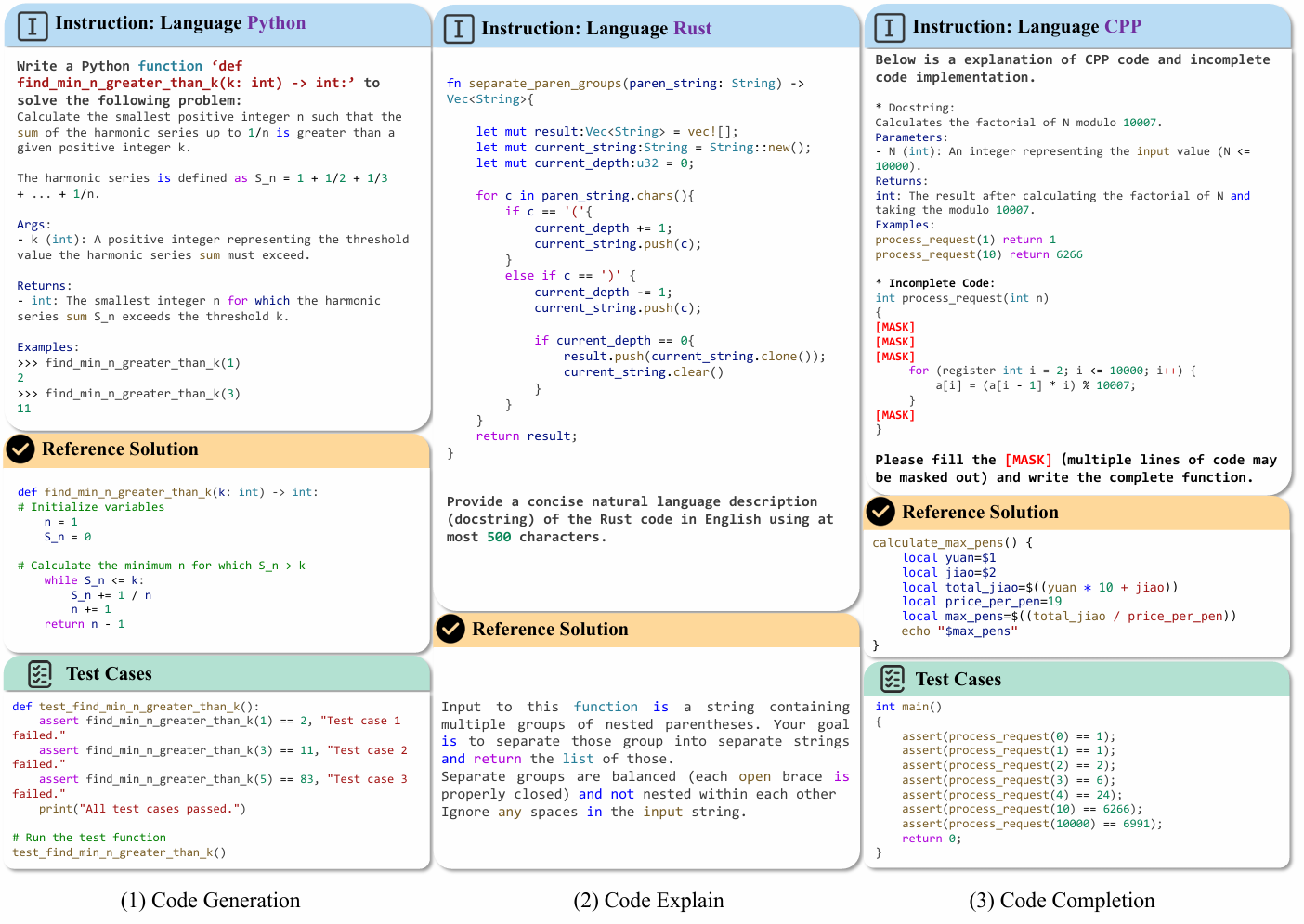
The data mainly consists of an instruction part (including function name, function description, and function call cases),a reference solution, and a test cases part. Left Figure: an example of the Lisp language. Middle Figure: a file processing programming task in AWK language. During the evaluation, the corresponding file processing result by the generated code will be compared with the reference answer. Right Figure: an example of the R language.

The data mainly consists of an instruction part (including a complete function), a reference Explanation. Left Figure: an example of the Kotlin language. Middle Figure: an example of the Lua language. Right Figure: an example of the HTML language.
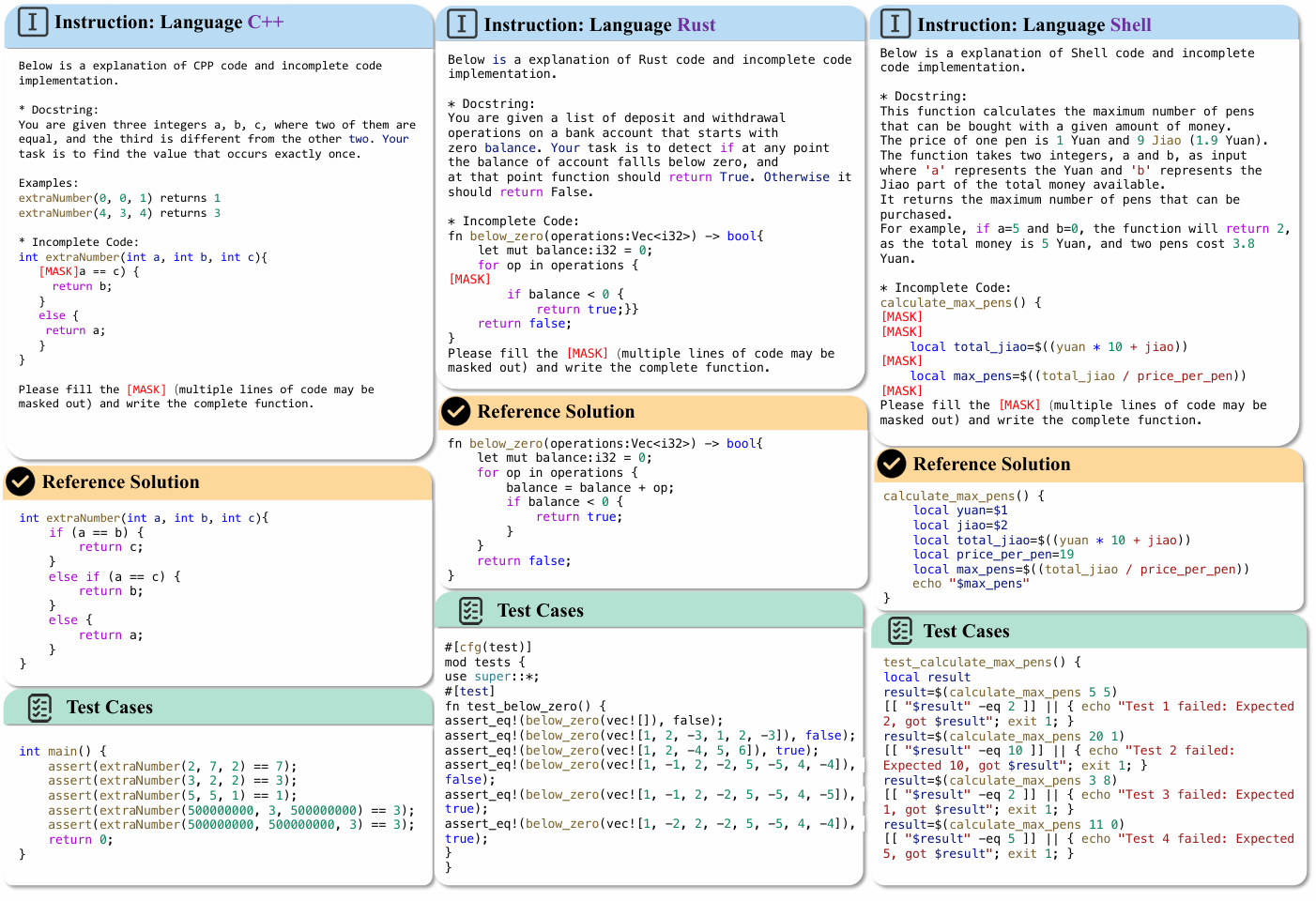
The data mainly consists of an instruction part (including an incomplete function ), a reference complete code solution and test cases. Left Figure: an span completion example of the C++ language. Middle Figure: a single-line completion example of the Rust language. Right Figure: a multiple-line completion example of the Shell language.
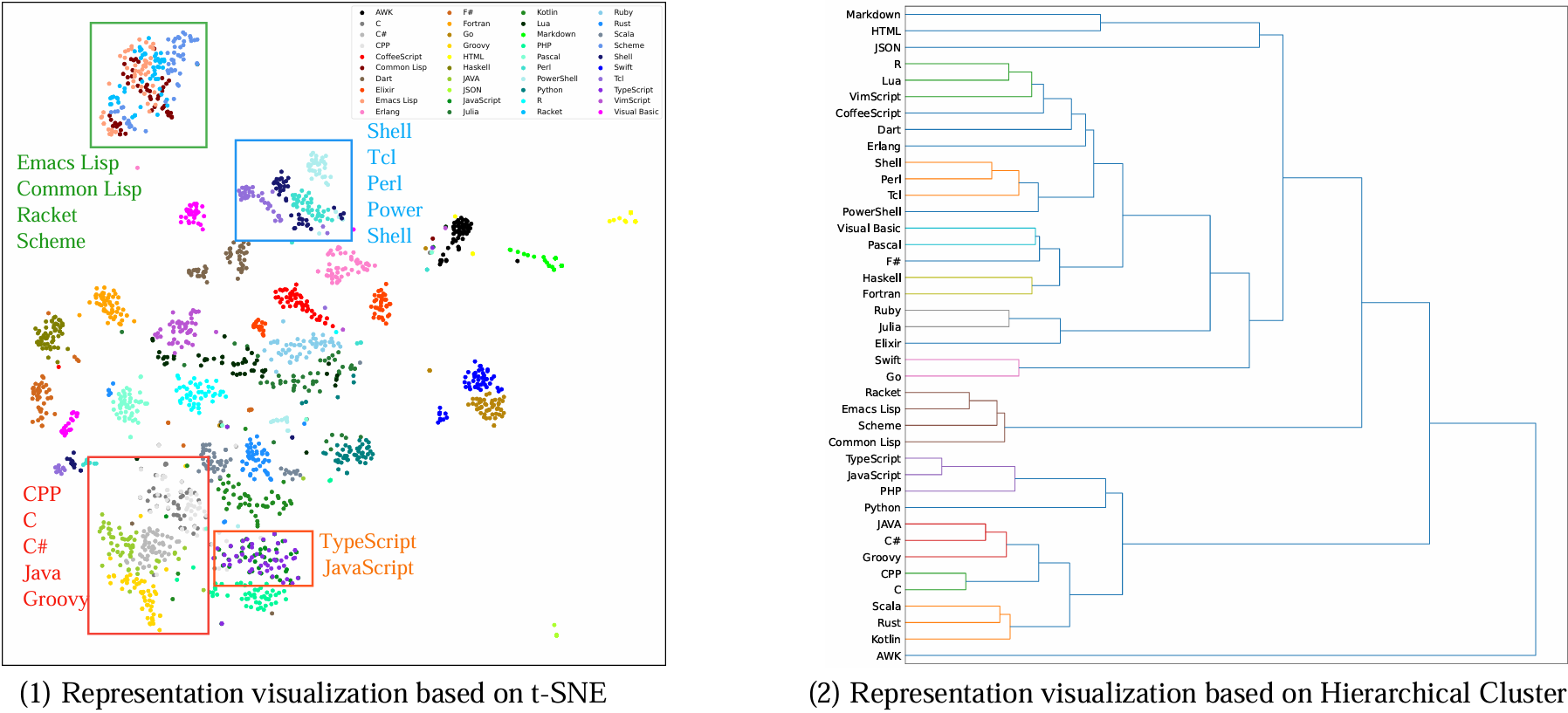
As shown in the Figure, we analyzed the programming languages in the McEval from their presentation perspective. We used CodeBERT to extract code representations from code snippets in McEval. The figure clearly shows that languages with similar syntax have closely related representations. For example, other functional programming languages similar to CommonLisp, as well as C, C++, Java, and scripting languages, exhibit high grammar similarity.